Summary
Originally PyTorch, used an eager mode where each PyTorch operation that forms the model is run independently as soon as it’s reached. PyTorch 2.0 introduced torch.compile to speed up PyTorch code over the default eager mode. In contrast to eager mode, the torch.compile pre-compiles the entire model into a single graph in a manner that’s optimal for running on a given hardware platform. AWS optimized the PyTorch torch.compile feature for AWS Graviton3 processors. This optimization results in up to 2x better performance for Hugging Face model inference (based on geomean of performance improvement for 33 models) and up to 1.35x better performance for TorchBench model inference (geomean of performance improvement for 45 models) compared to the default eager mode inference across several natural language processing (NLP), computer vision (CV), and recommendation models on AWS Graviton3-based Amazon EC2 instances. Starting with PyTorch 2.3.1, the optimizations are available in torch Python wheels and AWS Graviton PyTorch deep learning container (DLC).
In this blog post, we show how we optimized torch.compile performance on AWS Graviton3-based EC2 instances, how to use the optimizations to improve inference performance, and the resulting speedups.
Why torch.compile and what’s the goal?
In eager mode, operators in a model are run immediately as they are encountered. It’s easier to use, more suitable for machine learning (ML) researchers, and hence is the default mode. However, eager mode incurs runtime overhead because of redundant kernel launch and memory read overhead. Whereas in torch compile mode, operators are first synthesized into a graph, wherein one operator is merged with another to reduce and localize memory reads and total kernel launch overhead.
The goal for the AWS Graviton team was to optimize torch.compile backend for Graviton3 processors. PyTorch eager mode was already optimized for Graviton3 processors with Arm Compute Library (ACL) kernels using oneDNN (also known as MKLDNN). So, the question was, how to reuse those kernels in torch.compile mode to get the best of graph compilation and the optimized kernel performance together?
Results
The AWS Graviton team extended the torch inductor and oneDNN primitives that reused the ACL kernels and optimized compile mode performance on Graviton3 processors. Starting with PyTorch 2.3.1, the optimizations are available in the torch Python wheels and AWS Graviton DLC. Please see the Running an inference section that follows for the instructions on installation, runtime configuration, and how to run the tests.
To demonstrate the performance improvements, we used NLP, CV, and recommendation models from TorchBench and the most downloaded NLP models from Hugging Face across Question Answering, Text Classification, Token Classification, Translation, Zero-Shot Classification, Translation, Summarization, Feature Extraction, Text Generation, Text2Text Generation, Fill-Mask, and Sentence Similarity tasks to cover a wide variety of customer use cases.
We started with measuring TorchBench model inference latency, in milliseconds (msec), for the eager mode, which is marked 1.0 with a red dotted line in the following graph. Then we compared the improvements from torch.compile for the same model inference, the normalized results are plotted in the graph. You can see that for the 45 models we benchmarked, there is a 1.35x latency improvement (geomean for the 45 models).
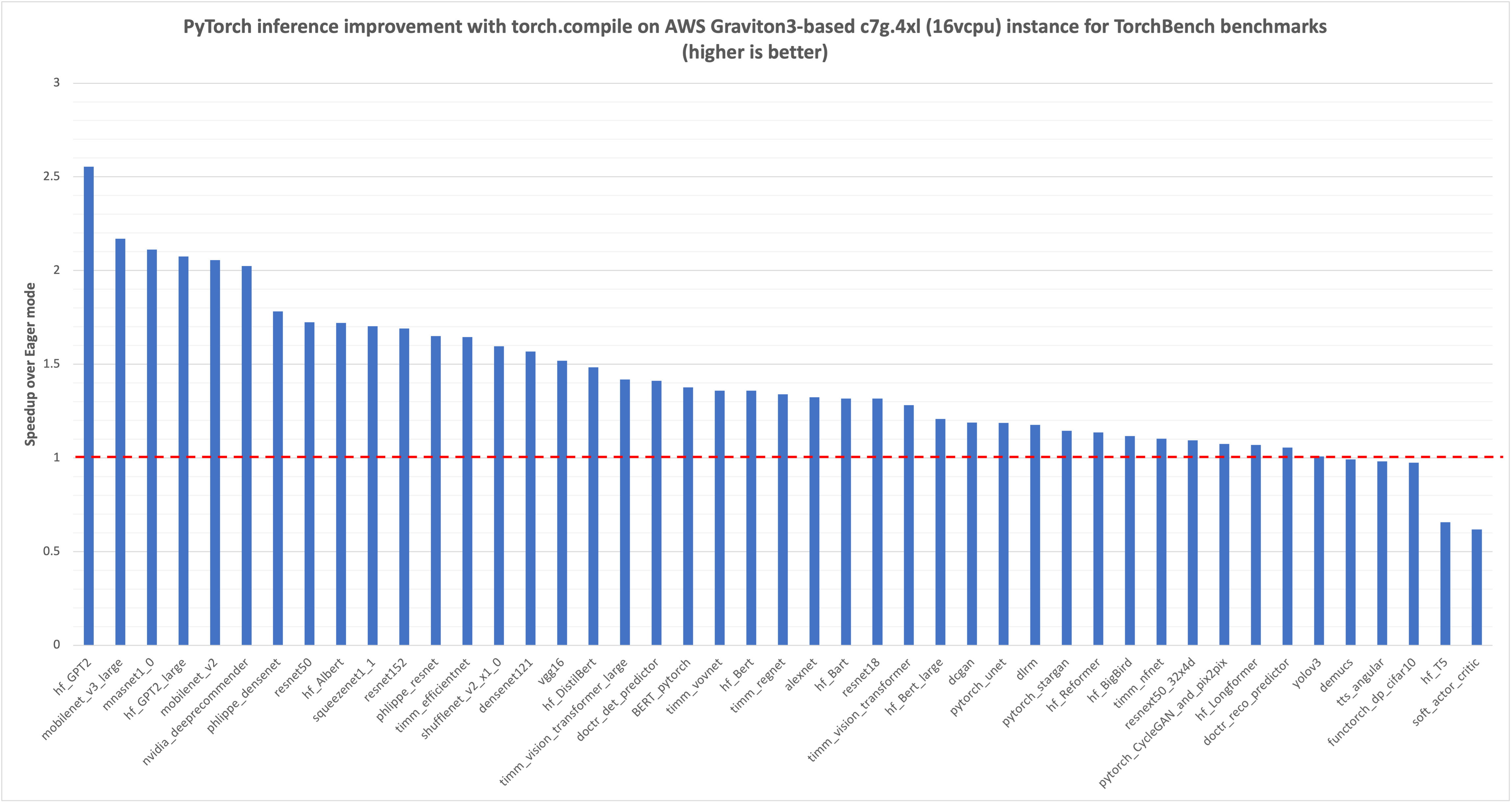
Image 1: PyTorch model inference performance improvement with torch.compile on AWS Graviton3-based c7g instance using TorchBench framework. The reference eager mode performance is marked as 1.0. (higher is better)
Similar to the preceding TorchBench inference performance graph, we started with measuring the Hugging Face NLP model inference latency, in msec, for the eager mode, which is marked 1.0 with a red dotted line in the following graph. Then we compared the improvements from torch.compile for the same model inference, the normalized results are plotted in the graph. You can see that for the 33 models we benchmarked, there is around 2x performance improvement (geomean for the 33 models).
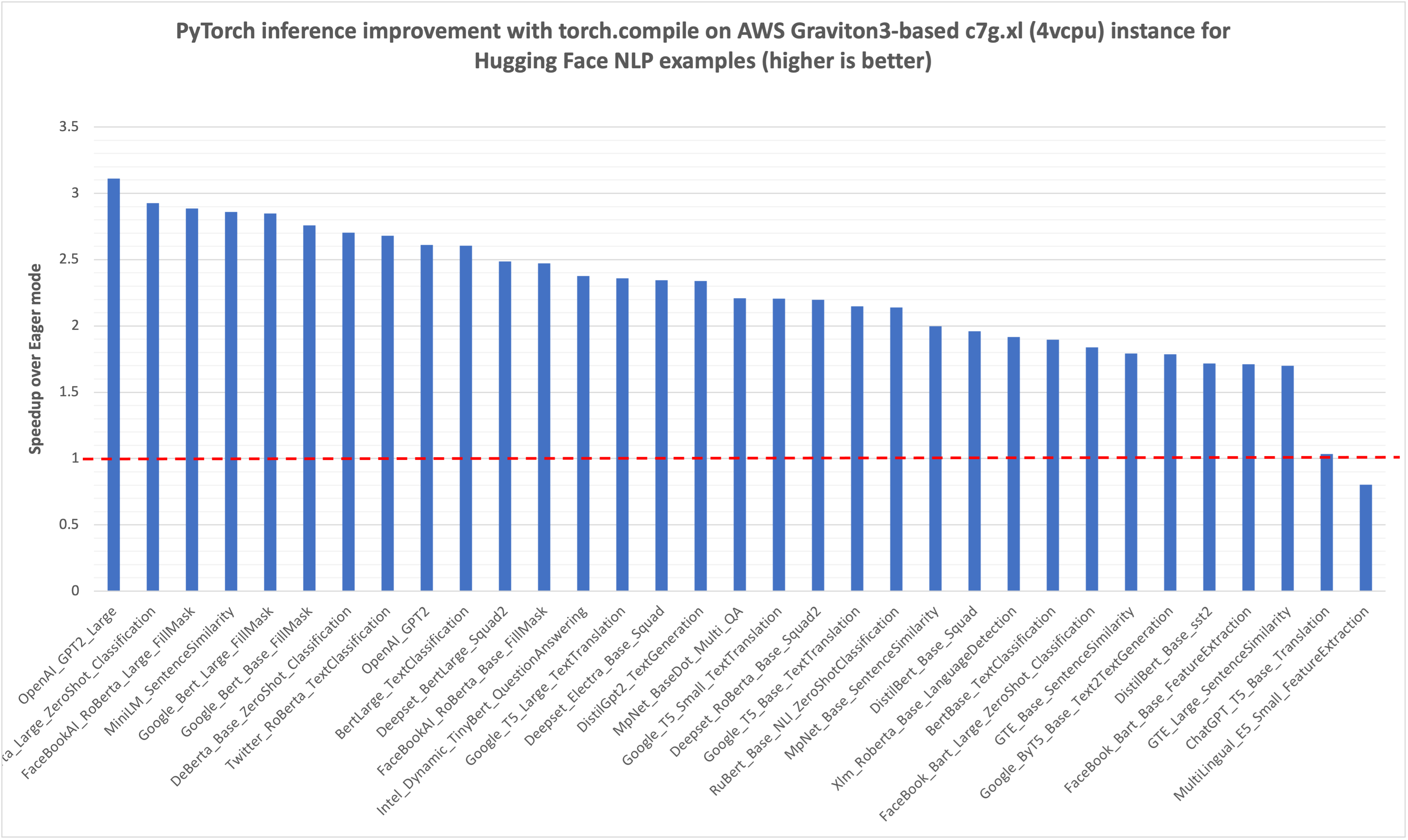
Image 2: Hugging Face NLP model inference performance improvement with torch.compile on AWS Graviton3-based c7g instance using Hugging Face example scripts. The reference eager mode performance is marked as 1.0. (higher is better)
Running an inference
Starting with PyTorch 2.3.1, the optimizations are available in the torch Python wheel and in AWS Graviton PyTorch DLC. This section shows how to run inference in eager and torch.compile modes using torch Python wheels and benchmarking scripts from Hugging Face and TorchBench repos.
To successfully run the scripts and reproduce the speedup numbers mentioned in this post, you need an instance from the Graviton3 family (c7g/r7g/m7g/hpc7g) of hardware. For this post, we used the c7g.4xl (16 vcpu) instance. The instance, the AMI details, and the required torch library versions are mentioned in the following snippet.
Instance: c7g.4xl instance
Region: us-west-2
AMI: ami-05cc25bfa725a144a (Ubuntu 22.04/Jammy with 6.5.0-1017-aws kernel)
# Install Python
sudo apt-get update
sudo apt-get install -y python3 python3-pip
# Upgrade pip3 to the latest version
python3 -m pip install --upgrade pip
# Install PyTorch and extensions
python3 -m pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1
The generic runtime tunings implemented for eager mode inference are equally applicable for the torch.compile mode, so, we set the following environment variables to further improve the torch.compile performance on AWS Graviton3 processors.
# Enable the fast math GEMM kernels, to accelerate fp32 inference with bfloat16 gemm
export DNNL_DEFAULT_FPMATH_MODE=BF16
# Enable Linux Transparent Huge Page (THP) allocations,
# to reduce the tensor memory allocation latency
export THP_MEM_ALLOC_ENABLE=1
# Set LRU Cache capacity to cache the primitives and avoid redundant
# memory allocations
export LRU_CACHE_CAPACITY=1024
TORCHBENCH BENCHMARKING SCRIPTS
TorchBench is a collection of open source benchmarks used to evaluate PyTorch performance. We benchmarked 45 models using the scripts from the TorchBench repo. Following code shows how to run the scripts for the eager mode and the compile mode with inductor backend.
# Set OMP_NUM_THREADS to number of vcpus, 16 for c7g.4xl instance
export OMP_NUM_THREADS=16
# Install the dependencies
sudo apt-get install -y libgl1-mesa-glx
sudo apt-get install -y libpangocairo-1.0-0
python3 -m pip install psutil numpy transformers pynvml numba onnx onnxruntime scikit-learn timm effdet gym doctr opencv-python h5py==3.10.0 python-doctr
# Clone pytorch benchmark repo
git clone https://github.com/pytorch/benchmark.git
cd benchmark
# PyTorch benchmark repo doesn't have any release tags. So,
# listing the commit we used for collecting the performance numbers
git checkout 9a5e4137299741e1b6fb7aa7f5a6a853e5dd2295
# Setup the models
python3 install.py
# Colect eager mode performance using the following command. The results will be
# stored at .userbenchmark/cpu/metric-<timestamp>.json.
python3 run_benchmark.py cpu --model BERT_pytorch,hf_Bert,hf_Bert_large,hf_GPT2,hf_Albert,hf_Bart,hf_BigBird,hf_DistilBert,hf_GPT2_large,dlrm,hf_T5,mnasnet1_0,mobilenet_v2,mobilenet_v3_large,squeezenet1_1,timm_efficientnet,shufflenet_v2_x1_0,timm_regnet,resnet50,soft_actor_critic,phlippe_densenet,resnet152,resnet18,resnext50_32x4d,densenet121,phlippe_resnet,doctr_det_predictor,timm_vovnet,alexnet,doctr_reco_predictor,vgg16,dcgan,yolov3,pytorch_stargan,hf_Longformer,timm_nfnet,timm_vision_transformer,timm_vision_transformer_large,nvidia_deeprecommender,demucs,tts_angular,hf_Reformer,pytorch_CycleGAN_and_pix2pix,functorch_dp_cifar10,pytorch_unet --test eval --metrics="latencies,cpu_peak_mem"
# Collect torch.compile mode performance with inductor backend
# and weights pre-packing enabled. The results will be stored at
# .userbenchmark/cpu/metric-<timestamp>.json
python3 run_benchmark.py cpu --model BERT_pytorch,hf_Bert,hf_Bert_large,hf_GPT2,hf_Albert,hf_Bart,hf_BigBird,hf_DistilBert,hf_GPT2_large,dlrm,hf_T5,mnasnet1_0,mobilenet_v2,mobilenet_v3_large,squeezenet1_1,timm_efficientnet,shufflenet_v2_x1_0,timm_regnet,resnet50,soft_actor_critic,phlippe_densenet,resnet152,resnet18,resnext50_32x4d,densenet121,phlippe_resnet,doctr_det_predictor,timm_vovnet,alexnet,doctr_reco_predictor,vgg16,dcgan,yolov3,pytorch_stargan,hf_Longformer,timm_nfnet,timm_vision_transformer,timm_vision_transformer_large,nvidia_deeprecommender,demucs,tts_angular,hf_Reformer,pytorch_CycleGAN_and_pix2pix,functorch_dp_cifar10,pytorch_unet --test eval --torchdynamo inductor --freeze_prepack_weights --metrics="latencies,cpu_peak_mem"
On successful completion of the inference runs, the script stores the results in JSON format. The following is the sample output:
{
"name": "cpu"
"environ": {
"pytorch_git_version": "d44533f9d073df13895333e70b66f81c513c1889"
},
"metrics": {
"BERT_pytorch-eval_latency": 56.3769865,
"BERT_pytorch-eval_cmem": 0.4169921875
}
}
HUGGING FACE BENCHMARKING SCRIPTS
Google T5 Small Text Translation model is one of the around 30 Hugging Face models we benchmarked. We’re using it as a sample model to demonstrate how to run inference in eager and compile modes. The additional configurations and APIs required to run it in compile mode are highlighted in BOLD. Save the following script as google_t5_small_text_translation.py.
import argparse
from transformers import T5Tokenizer, T5Model
import torch
from torch.profiler import profile, record_function, ProfilerActivity
import torch._inductor.config as config
config.cpp.weight_prepack=True
config.freezing=True
def test_inference(mode, num_iter):
tokenizer = T5Tokenizer.from_pretrained("t5-small")
model = T5Model.from_pretrained("t5-small")
input_ids = tokenizer(
"Studies have been shown that owning a dog is good for you", return_tensors="pt"
).input_ids # Batch size 1
decoder_input_ids = tokenizer("Studies show that", return_tensors="pt").input_ids # Batch size 1
if (mode == 'compile'):
model = torch.compile(model)
with torch.no_grad():
for _ in range(50):
outputs = model(input_ids=input_ids, decoder_input_ids=decoder_input_ids)
with profile(activities=[ProfilerActivity.CPU]) as prof:
with record_function("model_inference"):
for _ in range(num_iter):
outputs = model(input_ids=input_ids, decoder_input_ids=decoder_input_ids)
print(prof.key_averages().table(sort_by="self_cpu_time_total"))
def main() -> None:
global m, args
parser = argparse.ArgumentParser(__doc__)
parser.add_argument(
"-m",
"--mode",
choices=["eager", "compile"],
default="eager",
help="Which test to run.",
)
parser.add_argument(
"-n",
"--number",
type=int,
default=100,
help="how many iterations to run.",
)
args = parser.parse_args()
test_inference(args.mode, args.number)
if __name__ == "__main__":
main()
Run the script with the following steps:
# Set OMP_NUM_THREADS to number of vcpus to 4 because
# the scripts are running inference in sequence, and
# they don't need large number of vcpus
export OMP_NUM_THREADS=4
# Install the dependencies
python3 -m pip install transformers
# Run the inference script in Eager mode
# using number of iterations as 1 just to show the torch profiler output
# but for the benchmarking, we used 1000 iterations.
python3 google_t5_small_text_translation.py -n 1 -m eager
# Run the inference script in torch compile mode
python3 google_t5_small_text_translation.py -n 1 -m compile
On successful completion of the inference runs, the script prints the torch profiler output with the latency breakdown for the torch operators. The following is the sample output from torch profiler:
# Torch profiler output for the eager mode run on c7g.xl (4vcpu)
------------------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
------------------------ ------------ ------------ ------------ ------------ ------------ ------------
aten::mm 40.71% 12.502ms 40.71% 12.502ms 130.229us 96
model_inference 26.44% 8.118ms 100.00% 30.708ms 30.708ms 1
aten::bmm 6.85% 2.102ms 9.47% 2.908ms 80.778us 36
aten::matmul 3.73% 1.146ms 57.26% 17.583ms 133.205us 132
aten::select 1.88% 576.000us 1.90% 583.000us 0.998us 584
aten::transpose 1.51% 464.000us 1.83% 563.000us 3.027us 186
------------------------ ------------ ------------ ------------ ------------ ------------ -------------------
Self CPU time total: 30.708ms
# Torch profiler output for the compile mode run for the same model on the same instance
--------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
--------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
mkldnn::_linear_pointwise 37.98% 5.461ms 45.91% 6.602ms 68.771us 96
Torch-Compiled Region 29.56% 4.251ms 98.53% 14.168ms 14.168ms 1
aten::bmm 14.90% 2.143ms 21.73% 3.124ms 86.778us 36
aten::select 4.51% 648.000us 4.62% 665.000us 1.155us 576
aten::view 3.29% 473.000us 3.29% 473.000us 1.642us 288
aten::empty 2.53% 364.000us 2.53% 364.000us 3.165us 115
--------------------------------- ------------ ------------ ------------ ------------ ------------ --------------------
Self CPU time total: 14.379ms
Technical deep dive: What are the challenges and optimization details
Underpinning torch.compile are new technologies – TorchDynamo, AOTDispatcher, and TorchInductor.
TorchDynamo captures PyTorch programs safely using Python Frame Evaluation Hooks
AOTDispatcher overloads PyTorch’s autograd engine as a tracing autodiff for generating ahead-of-time backward traces.
TorchInductor is a deep learning compiler that generates fast code for multiple accelerators and backends.
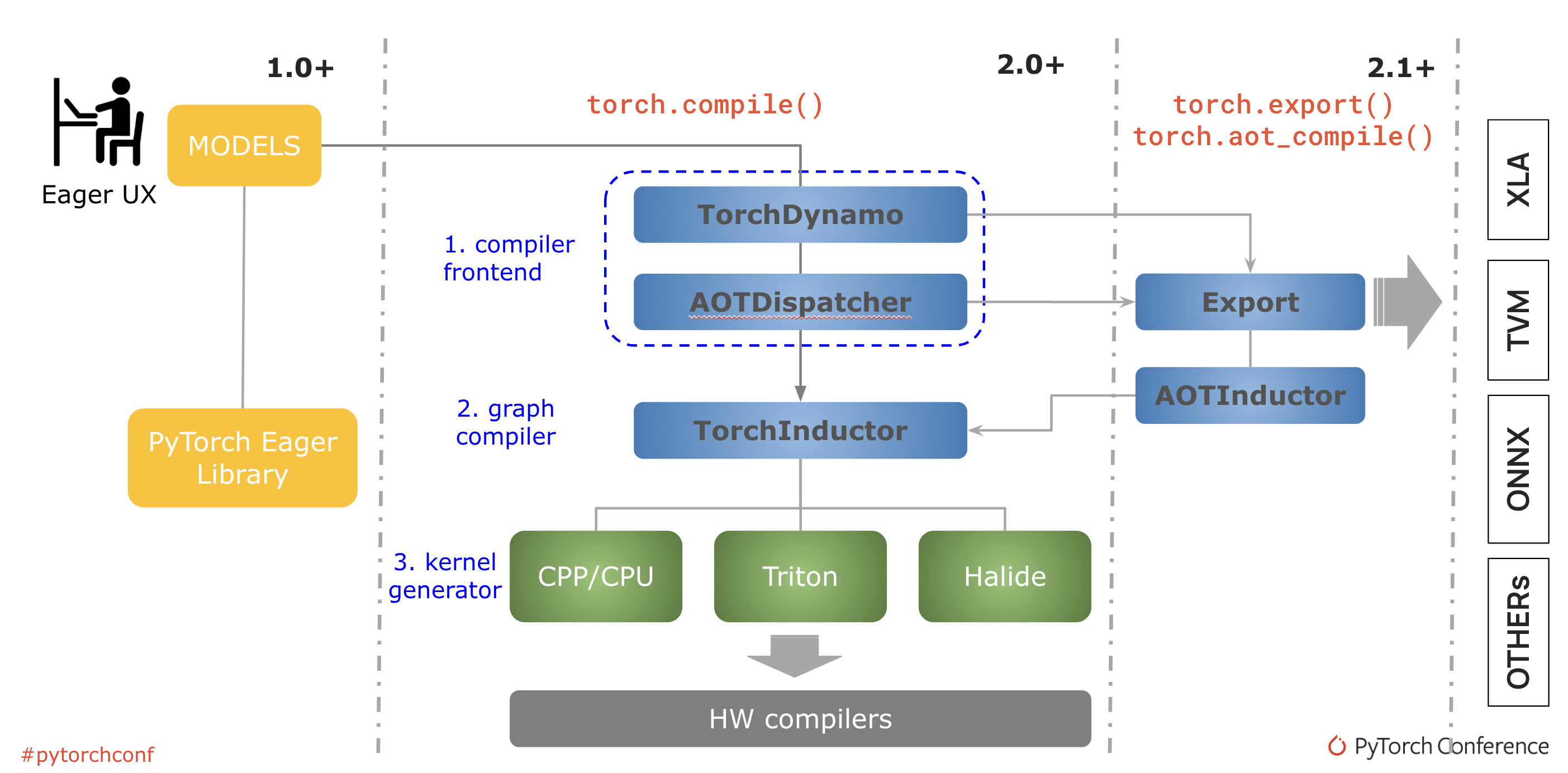
Image 3: The PyTorch compilation process
When torch.compile is invoked, torch dynamo rewrites Python bytecode to extract sequences of PyTorch operations into an FX Graph, which is then compiled with inductor backend. For a typical inference scenario where the graph is frozen and gradient calculations are disabled, the inductor invokes platform specific optimizations like graph rewrite into more performant operators, operator fusion, and weights pre-packing.
However, on Graviton3, the inductor wasn’t able to perform any of those optimizations because there was no aarch64 backend defined. To fix this, we extended the inductor’s FX passes to pick oneDNN operators for linear layer compilation on Graviton3 processors with ACL backend. The code snippet for this follows:
packed_weight_op = (
mkldnn._reorder_linear_weight
if (is_bf16_weight or mkldnn._is_mkldnn_acl_supported())
packed_linear_inputs: Tuple[Any, ...] = (input, packed_weight_node)
if is_bf16_weight or mkldnn._is_mkldnn_acl_supported():
packed_linear_inputs += (bias, "none", [], "")
packed_linear_op = mkldnn._linear_pointwise.default
After this was done, the FX pass was successful in compiling the matmul operators to linear_pointwise . The following snippet highlights the matmul operator in the original model:
%attention_scores : [num_users=1] = call_function[target=torch.matmul](args = (%query_layer, %transpose), kwargs = {})
%attention_scores_1 : [num_users=1] = call_function[target=operator.truediv](args = (%attention_scores, 8.0), kwargs = {})
%attention_scores_2 : [num_users=1] = call_function[target=operator.add](args = (%attention_scores_1, %extended_attention_mask_3), kwargs = {})
The following snippet highlights the linear_pointwise operator in the compiled graph:
%_linear_pointwise_default_140 : [num_users=2] = call_function[target=torch.ops.mkldnn._linear_pointwise.default](args = (%add_7, %_frozen_param278, %_frozen_param16, none, [], ), kwargs = {})
%mul_5 : [num_users=1] = call_function[target=torch.ops.aten.mul.Tensor](args = (%_linear_pointwise_default_140, 0.5), kwargs = {})
%mul_6 : [num_users=1] = call_function[target=torch.ops.aten.mul.Tensor](args = (%_linear_pointwise_default_140, 0.7071067811865476), kwargs = {})
%erf : [num_users=1] = call_function[target=torch.ops.aten.erf.default](args = (%mul_6,), kwargs = {})
%add_8 : [num_users=1] = call_function[target=torch.ops.aten.add.Tensor](args = (%erf, 1), kwargs = {})
This completes the torch inductor changes required to compile the graph into optimized operators on AWS Graviton3 processors. Next comes the actual inference where the compiled graph is dispatched to be run. OneDNN with ACL was the backend we chose during the inductor compilation, so, the new operators were dispatched to oneDNN as expected, for example, mkldnn._linear_pointwise. However, due to gaps in oneDNN ACL primitives, the operators were run with C++ reference kernels instead of the optimized ACL kernels. Hence, the compile performance was still significantly behind the eager mode performance.
There were mainly three areas where oneDNN ACL primitives lack support for torch.compile mode. The following section talks about them in detail.
1. ACL primitives didn’t have support for weights in blocked layout
ACL primitives originally designed for eager mode supported weights only in the standard channels last (NHWC) format, without any pre-packing. Whereas weights pre-packing into blocked layout is one of the main optimizations in the inductor compilation passes where the weights are reordered into blocks specific to the runtime platform. This avoids the redundant and on-the-fly reorders when running the General Matrix Multiplication (GEMM), which otherwise would be the bottleneck for inference performance. But the ACL primitives didn’t have support for blocked layout and hence the operators were run with oneDNN C++ reference kernels instead.
2. Mixed precision primitives weren’t supported in oneDNN
AWS Graviton3 processors support bfloat16 MMLA instructions which can be used to accelerate fp32 inference with bfloat16 GEMM as a mixed precision compute. ACL supports bfloat16 mixed precision GEMM kernels, and are integrated into oneDNN as a fast math compute option for the existing fp32 operators. However, the fast math approach didn’t work for compile mode because of weights pre-packing optimization. The compile mode requires explicit mixed precision primitive implementation in oneDNN in order to use bfloat16 acceleration.
3. ACL primitives didn’t support fused kernels for some of the activation functions
In eager mode, operators are dispatched individually because the model is run independently as soon as it’s reached. Whereas in compile mode, operator fusion is another important optimization where the operators are fused for runtime efficiency. For example, Gaussian Error Linear Unit (GELU) is one of the most widely used activation functions in transformers-based neural network architectures. So, it’s typical to have a linear layer (with matrix multiplications) followed by GELU activation. As part of compiling the model into efficient operators, the torch inductor fuses matmul and GELU into a single linearpointwise+gelu operator. However, oneDNN ACL primitives didn’t have the support for fused kernels with GELU.
We addressed these gaps by extending oneDNN primitives to handle the additional layouts and new primitive definitions. The following sections talk about the optimizations in detail.
Optimization 1: Extended ACL primitives to accept weight tensors in blocked layout
We extended the ACL primitives to accept blocked layout in addition to the the standard NHWC format. The code snippet for this is as follows:
const bool is_weights_md_format_ok
= utils::one_of(weights_format_kind_received,
format_kind::any, format_kind::blocked);
const memory_desc_t weights_md_received = weights_md_;
acl_utils::reorder_to_weight_format(aip.wei_tensor_info,
weights_md_, expected_weight_format, inner_dim, o_dim,
remaining_dims, {});
ACL_CHECK_SUPPORT(
(weights_format_kind_received == format_kind::blocked)
&& !(dnnl_memory_desc_equal(
&weights_md_received, &weights_md_)),
"specified blocked format not supported by ACL, use "
"format_kind_t::any to find a supported blocked format for "
"your platform");
Optimization 2: Defined new ACL primitives to handle mixed precision operators (weights in bfloat16 and activations in fp32)
We defined mixed precision primitive definitions and updated the existing oneDNN ACL fp32 primitives to handle bfloat16 tensors.
/* With graph compilation, we are able to reorder and pre-pack the weights during the model load
* and compilation phase itself so that redundant and on-the-fly reorders can be avoided.
* This primitive definition is to support gemm fastmath mode for the compile scenario where src is
* in fp32 and weights are in bf16
*/
{{forward, f32, bf16, f32}, {
CPU_INSTANCE_AARCH64_ACL(acl_inner_product_fwd_t)
nullptr,
}},
Optimization 3: Disabled operator fusion pass in torch inductor
We bypassed the operator fusion pass in torch inductor so that the compiled graph doesn’t contain GELU fused operators. This is a temporary solution to enable ACL kernels in torch.compile. There is a work in progress to enable operator fusion pass for the future PyTorch releases. With this workaround, we were able to successfully dispatch the linear layer to ACL. As shown in the following torch.profiler output, the aten::addmm (one of the variants of the matmul operator) and aten::gelu in the original model (as highlighted in Image 4) was compiled to mkldnn::_linear_pointwise without gelu operator fusion (as highlighted in Image 5).
--------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
--------------------------- ------------ ------------ ------------ ------------ ------------ ------------
aten::addmm 73.32% 46.543ms 74.49% 47.287ms 647.767us 73
model_inference 9.92% 6.296ms 100.00% 63.479ms 63.479ms 1
aten::bmm 4.37% 2.776ms 5.46% 3.467ms 144.458us 24
aten::copy_ 1.74% 1.102ms 1.74% 1.102ms 8.103us 136
aten::gelu 1.50% 950.000us 1.50% 950.000us 79.167us 12
Image 4: torch.profiler output for Hugging Face bert base model inference in Eager mode, showing addmm and gelu operators
----------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
----------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
mkldnn::_linear_pointwise 53.61% 15.529ms 57.53% 16.665ms 228.288us 73
Torch-Compiled Region 36.95% 10.705ms 99.31% 28.769ms 28.769ms 1
aten::_scaled_dot_product_flash_attention_for_cpu 3.67% 1.064ms 4.43% 1.284ms 107.000us 12
aten::view 1.97% 572.000us 1.97% 572.000us 2.509us 228
aten::empty 1.38% 399.000us 1.38% 399.000us 3.270us 122
Image 5: torch.profiler output for Hugging Face Bert base model inference in torch.compile mode, showing linear_pointwise operator without gelu fusion
Lastly, the gelu operator was compiled into erf (error function) and was dispatched to an inductor auto vectorization backend. The following snippets show the erf operator in the compiled graph and running it using libm.so.
%_linear_pointwise_default_140 : [num_users=2] = call_function[target=torch.ops.mkldnn._linear_pointwise.default](args = (%add_7, %_frozen_param278, %_frozen_param16, none, [], ), kwargs = {})
%mul_5 : [num_users=1] = call_function[target=torch.ops.aten.mul.Tensor](args = (%_linear_pointwise_default_140, 0.5), kwargs = {})
%mul_6 : [num_users=1] = call_function[target=torch.ops.aten.mul.Tensor](args = (%_linear_pointwise_default_140, 0.7071067811865476), kwargs = {})
%erf : [num_users=1] = call_function[target=torch.ops.aten.erf.default](args = (%mul_6,), kwargs = {})
%add_8 : [num_users=1] = call_function[target=torch.ops.aten.add.Tensor](args = (%erf, 1), kwargs = {})
Image 6: snippet after post grad pass showing erf function in the compiled graph
0.82% 0.40% python3 libm.so.6 [.] erff32
0.05% 0.00% python3 libtorch_python.so [.] torch::autograd::THPVariable_erf
0.05% 0.00% python3 libtorch_cpu.so [.] at::_ops::erf::call
Image 7: Linux perf report showing erf dispatch to libm.so
With this work, we were able to optimize torch.compile performance on Graviton3 processors by using inductor graph compilation along with the oneDNN+ACL backend.
TorchBench enhancements
To demonstrate the torch.compile performance improvements on AWS Graviton3 processors, we extended TorchBench framework to add a new argument to enable graph freeze and weights pre-packing and disable torch auto grad for eval test mode. The code snippet for this is as follows:
parser.add_argument(
"—freeze_prepack_weights",
action='store_true',
help="set to freeze the graph and prepack weights",
)
if args.freeze_prepack_weights:
torch._inductor.config.freezing=True
torch._inductor.config.cpp.weight_prepack=True
Image 8: Added freeze_prepack_weights option for torchdynamo backend in TorchBench to demonstrate torch.compile performance improvements on AWS Graviton3 processors
We have upstreamed all the optimizations, and starting with PyTorch 2.3.1, these are supported in torch Python wheels and AWS Graviton PyTorch DLC.
What’s next
Next, we’re extending the torch inductor CPU backend support to compile Llama model, and adding support for fused GEMM kernels to enable torch inductor operator fusion optimization on AWS Graviton3 processors.
Conclusion
In this tutorial, we covered how we optimized torch.compile performance on AWS Graviton3-based EC2 instances, how to use the optimizations to improve PyTorch model inference performance, and demonstrated the resulting speedups. We hope that you will give it a try! If you need any support with ML software on Graviton, please open an issue on the AWS Graviton Technical Guide GitHub.
Acknowledgements
We would like to thank the PyTorch community for the baseline torch.compile framework and their continued efforts to optimize it further.
References: https://pytorch.org/assets/pytorch2-2.pdf
Author
Sunita Nadampalli is a Software Development Manager and AI/ML expert at AWS. She leads AWS Graviton software performance optimizations for AI/ML and HPC workloads. She is passionate about open source software development and delivering high-performance and sustainable software solutions for SoCs based on the Arm ISA.
