


Note
Click here to download the full example code
Introduction to ONNX || Exporting a PyTorch model to ONNX || Extending the ONNX Registry
Extending the ONNX Registry¶
Authors: Ti-Tai Wang (titaiwang@microsoft.com)
Overview¶
This tutorial is an introduction to ONNX registry, which empowers users to implement new ONNX operators or even replace existing operators with a new implementation.
During the model export to ONNX, the PyTorch model is lowered to an intermediate representation composed of ATen operators. While ATen operators are maintained by PyTorch core team, it is the responsibility of the ONNX exporter team to independently implement each of these operators to ONNX through ONNX Script. The users can also replace the behavior implemented by the ONNX exporter team with their own implementation to fix bugs or improve performance for a specific ONNX runtime.
The ONNX Registry manages the mapping between PyTorch operators and the ONNX operators counterparts and provides APIs to extend the registry.
In this tutorial, we will cover three scenarios that require extending the ONNX registry with custom operators:
Unsupported ATen operators
Custom operators with existing ONNX Runtime support
Custom operators without ONNX Runtime support
Unsupported ATen operators¶
Although the ONNX exporter team does their best efforts to support all ATen operators, some of them might not be supported yet. In this section, we will demonstrate how you can add unsupported ATen operators to the ONNX Registry.
Note
The steps to implement unsupported ATen operators are the same to replace the implementation of an existing
ATen operator with a custom implementation.
Because we don’t actually have an unsupported ATen operator to use in this tutorial, we are going to leverage
this and replace the implementation of aten::add.Tensor with a custom implementation the same way we would
if the operator was not present in the ONNX Registry.
When a model cannot be exported to ONNX due to an unsupported operator, the ONNX exporter will show an error message similar to:
RuntimeErrorWithDiagnostic: Unsupported FX nodes: {'call_function': ['aten.add.Tensor']}.
The error message indicates that the fully qualified name of unsupported ATen operator is aten::add.Tensor.
The fully qualified name of an operator is composed of the namespace, operator name, and overload following
the format namespace::operator_name.overload.
To add support for an unsupported ATen operator or to replace the implementation for an existing one, we need:
The fully qualified name of the ATen operator (e.g.
aten::add.Tensor). This information is always present in the error message as show above.The implementation of the operator using ONNX Script. ONNX Script is a prerequisite for this tutorial. Please make sure you have read the ONNX Script tutorial before proceeding.
Because aten::add.Tensor is already supported by the ONNX Registry, we will demonstrate how to replace it with a
custom implementation, but keep in mind that the same steps apply to support new unsupported ATen operators.
This is possible because the OnnxRegistry allows users to override an operator registration.
We will override the registration of aten::add.Tensor with our custom implementation and verify it exists.
import torch
import onnxruntime
import onnxscript
from onnxscript import opset18 # opset 18 is the latest (and only) supported version for now
class Model(torch.nn.Module):
def forward(self, input_x, input_y):
return torch.ops.aten.add(input_x, input_y) # generates a aten::add.Tensor node
input_add_x = torch.randn(3, 4)
input_add_y = torch.randn(3, 4)
aten_add_model = Model()
# Now we create a ONNX Script function that implements ``aten::add.Tensor``.
# The function name (e.g. ``custom_aten_add``) is displayed in the ONNX graph, so we recommend to use intuitive names.
custom_aten = onnxscript.values.Opset(domain="custom.aten", version=1)
# NOTE: The function signature must match the signature of the unsupported ATen operator.
# https://github.com/pytorch/pytorch/blob/main/aten/src/ATen/native/native_functions.yaml
# NOTE: All attributes must be annotated with type hints.
@onnxscript.script(custom_aten)
def custom_aten_add(input_x, input_y, alpha: float = 1.0):
alpha = opset18.CastLike(alpha, input_y)
input_y = opset18.Mul(input_y, alpha)
return opset18.Add(input_x, input_y)
# Now we have everything we need to support unsupported ATen operators.
# Let's register the ``custom_aten_add`` function to ONNX registry, and export the model to ONNX again.
onnx_registry = torch.onnx.OnnxRegistry()
onnx_registry.register_op(
namespace="aten", op_name="add", overload="Tensor", function=custom_aten_add
)
print(f"aten::add.Tensor is supported by ONNX registry: \
{onnx_registry.is_registered_op(namespace='aten', op_name='add', overload='Tensor')}"
)
export_options = torch.onnx.ExportOptions(onnx_registry=onnx_registry)
onnx_program = torch.onnx.dynamo_export(
aten_add_model, input_add_x, input_add_y, export_options=export_options
)
Now let’s inspect the model and verify the model has a custom_aten_add instead of aten::add.Tensor.
The graph has one graph node for custom_aten_add, and inside of it there are four function nodes, one for each
operator, and one for constant attribute.
# graph node domain is the custom domain we registered
assert onnx_program.model_proto.graph.node[0].domain == "custom.aten"
assert len(onnx_program.model_proto.graph.node) == 1
# graph node name is the function name
assert onnx_program.model_proto.graph.node[0].op_type == "custom_aten_add"
# function node domain is empty because we use standard ONNX operators
assert onnx_program.model_proto.functions[0].node[3].domain == ""
# function node name is the standard ONNX operator name
assert onnx_program.model_proto.functions[0].node[3].op_type == "Add"
This is how custom_aten_add_model looks in the ONNX graph using Netron:
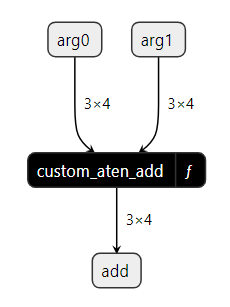
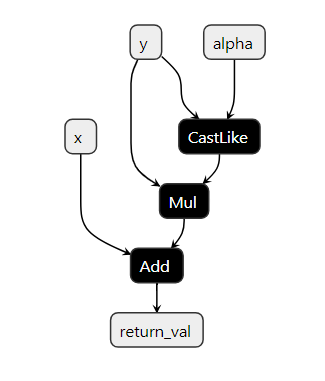
Inside the custom_aten_add function, we can see the three ONNX nodes we
used in the function (CastLike, Add, and Mul), and one Constant attribute:
This was all that we needed to register the new ATen operator into the ONNX Registry. As an additional step, we can use ONNX Runtime to run the model, and compare the results with PyTorch.
# Use ONNX Runtime to run the model, and compare the results with PyTorch
onnx_program.save("./custom_add_model.onnx")
ort_session = onnxruntime.InferenceSession(
"./custom_add_model.onnx", providers=['CPUExecutionProvider']
)
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
onnx_input = onnx_program.adapt_torch_inputs_to_onnx(input_add_x, input_add_y)
onnxruntime_input = {k.name: to_numpy(v) for k, v in zip(ort_session.get_inputs(), onnx_input)}
onnxruntime_outputs = ort_session.run(None, onnxruntime_input)
torch_outputs = aten_add_model(input_add_x, input_add_y)
torch_outputs = onnx_program.adapt_torch_outputs_to_onnx(torch_outputs)
assert len(torch_outputs) == len(onnxruntime_outputs)
for torch_output, onnxruntime_output in zip(torch_outputs, onnxruntime_outputs):
torch.testing.assert_close(torch_output, torch.tensor(onnxruntime_output))
Custom operators with existing ONNX Runtime support¶
In this case, the user creates a model with standard PyTorch operators, but the ONNX runtime (e.g. Microsoft’s ONNX Runtime) can provide a custom implementation for that kernel, effectively replacing the existing implementation in the ONNX Registry. Another use case is when the user wants to use a custom implementation of an existing ONNX operator to fix a bug or improve performance of a specific operator. To achieve this, we only need to register the new implementation with the existing ATen fully qualified name.
In the following example, we use the com.microsoft.Gelu from ONNX Runtime,
which is not the same Gelu from ONNX spec. Thus, we register the Gelu with
the namespace com.microsoft and operator name Gelu.
Before we begin, let’s check whether aten::gelu.default is really supported by the ONNX registry.
onnx_registry = torch.onnx.OnnxRegistry()
print(f"aten::gelu.default is supported by ONNX registry: \
{onnx_registry.is_registered_op(namespace='aten', op_name='gelu', overload='default')}")
In our example, aten::gelu.default operator is supported by the ONNX registry,
so onnx_registry.is_registered_op() returns True.
class CustomGelu(torch.nn.Module):
def forward(self, input_x):
return torch.ops.aten.gelu(input_x)
# com.microsoft is an official ONNX Runtime namspace
custom_ort = onnxscript.values.Opset(domain="com.microsoft", version=1)
# NOTE: The function signature must match the signature of the unsupported ATen operator.
# https://github.com/pytorch/pytorch/blob/main/aten/src/ATen/native/native_functions.yaml
# NOTE: All attributes must be annotated with type hints.
@onnxscript.script(custom_ort)
def custom_aten_gelu(input_x, approximate: str = "none"):
# We know com.microsoft::Gelu is supported by ONNX Runtime
# It's only not supported by ONNX
return custom_ort.Gelu(input_x)
onnx_registry = torch.onnx.OnnxRegistry()
onnx_registry.register_op(
namespace="aten", op_name="gelu", overload="default", function=custom_aten_gelu)
export_options = torch.onnx.ExportOptions(onnx_registry=onnx_registry)
aten_gelu_model = CustomGelu()
input_gelu_x = torch.randn(3, 3)
onnx_program = torch.onnx.dynamo_export(
aten_gelu_model, input_gelu_x, export_options=export_options
)
Let’s inspect the model and verify the model uses custom_aten_gelu() instead of
aten::gelu. Note the graph has one graph nodes for
custom_aten_gelu, and inside custom_aten_gelu, there is a function
node for Gelu with namespace com.microsoft.
# graph node domain is the custom domain we registered
assert onnx_program.model_proto.graph.node[0].domain == "com.microsoft"
# graph node name is the function name
assert onnx_program.model_proto.graph.node[0].op_type == "custom_aten_gelu"
# function node domain is the custom domain we registered
assert onnx_program.model_proto.functions[0].node[0].domain == "com.microsoft"
# function node name is the node name used in the function
assert onnx_program.model_proto.functions[0].node[0].op_type == "Gelu"
The following diagram shows custom_aten_gelu_model ONNX graph using Netron:
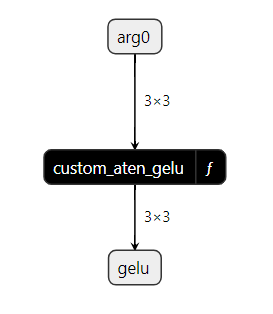
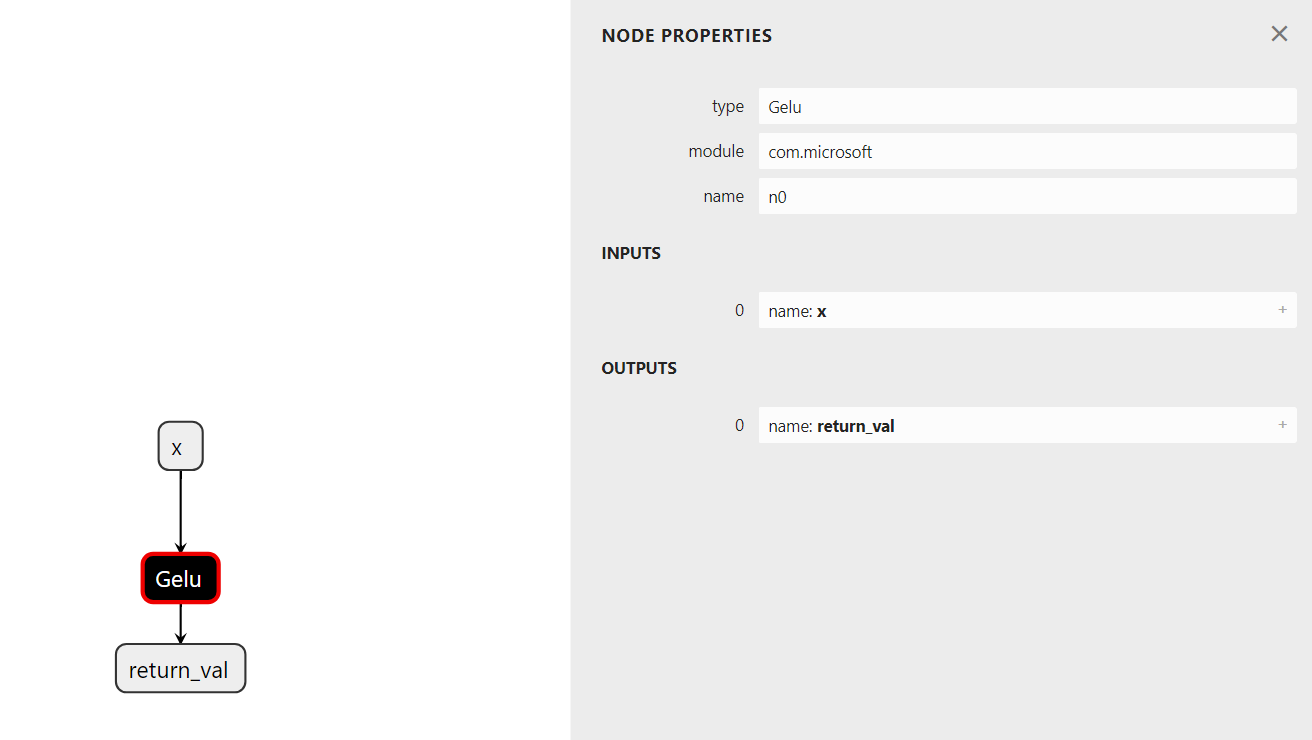
Inside the custom_aten_gelu function, we can see the Gelu node from module
com.microsoft used in the function:
That is all we need to do. As an additional step, we can use ONNX Runtime to run the model, and compare the results with PyTorch.
onnx_program.save("./custom_gelu_model.onnx")
ort_session = onnxruntime.InferenceSession(
"./custom_gelu_model.onnx", providers=['CPUExecutionProvider']
)
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
onnx_input = onnx_program.adapt_torch_inputs_to_onnx(input_gelu_x)
onnxruntime_input = {k.name: to_numpy(v) for k, v in zip(ort_session.get_inputs(), onnx_input)}
onnxruntime_outputs = ort_session.run(None, onnxruntime_input)
torch_outputs = aten_gelu_model(input_gelu_x)
torch_outputs = onnx_program.adapt_torch_outputs_to_onnx(torch_outputs)
assert len(torch_outputs) == len(onnxruntime_outputs)
for torch_output, onnxruntime_output in zip(torch_outputs, onnxruntime_outputs):
torch.testing.assert_close(torch_output, torch.tensor(onnxruntime_output))
Custom operators without ONNX Runtime support¶
In this case, the operator is not supported by any ONNX runtime, but we would like to use it as custom operator in ONNX graph. Therefore, we need to implement the operator in three places:
PyTorch FX graph
ONNX Registry
ONNX Runtime
In the following example, we would like to use a custom operator that takes one tensor input, and returns one output. The operator adds the input to itself, and returns the rounded result.
Custom Ops Registration in PyTorch FX Graph (Beta)¶
Firstly, we need to implement the operator in PyTorch FX graph.
This can be done by using torch._custom_op.
# NOTE: This is a beta feature in PyTorch, and is subject to change.
from torch._custom_op import impl as custom_op
@custom_op.custom_op("mylibrary::addandround_op")
def addandround_op(tensor_x: torch.Tensor) -> torch.Tensor:
...
@addandround_op.impl_abstract()
def addandround_op_impl_abstract(tensor_x):
return torch.empty_like(tensor_x)
@addandround_op.impl("cpu")
def addandround_op_impl(tensor_x):
return torch.round(tensor_x + tensor_x) # add x to itself, and round the result
torch._dynamo.allow_in_graph(addandround_op)
class CustomFoo(torch.nn.Module):
def forward(self, tensor_x):
return addandround_op(tensor_x)
input_addandround_x = torch.randn(3)
custom_addandround_model = CustomFoo()
Custom Ops Registration in ONNX Registry¶
For the step 2 and 3, we need to implement the operator in ONNX registry.
In this example, we will implement the operator in ONNX registry
with the namespace test.customop and operator name CustomOpOne,
and CustomOpTwo. These two ops are registered and built in
cpu_ops.cc.
custom_opset = onnxscript.values.Opset(domain="test.customop", version=1)
# NOTE: The function signature must match the signature of the unsupported ATen operator.
# https://github.com/pytorch/pytorch/blob/main/aten/src/ATen/native/native_functions.yaml
# NOTE: All attributes must be annotated with type hints.
@onnxscript.script(custom_opset)
def custom_addandround(input_x):
# The same as opset18.Add(x, x)
add_x = custom_opset.CustomOpOne(input_x, input_x)
# The same as opset18.Round(x, x)
round_x = custom_opset.CustomOpTwo(add_x)
# Cast to FLOAT to match the ONNX type
return opset18.Cast(round_x, to=1)
onnx_registry = torch.onnx.OnnxRegistry()
onnx_registry.register_op(
namespace="mylibrary", op_name="addandround_op", overload="default", function=custom_addandround
)
export_options = torch.onnx.ExportOptions(onnx_registry=onnx_registry)
onnx_program = torch.onnx.dynamo_export(
custom_addandround_model, input_addandround_x, export_options=export_options
)
onnx_program.save("./custom_addandround_model.onnx")
The onnx_program exposes the exported model as protobuf through onnx_program.model_proto.
The graph has one graph nodes for custom_addandround, and inside custom_addandround,
there are two function nodes, one for each operator.
assert onnx_program.model_proto.graph.node[0].domain == "test.customop"
assert onnx_program.model_proto.graph.node[0].op_type == "custom_addandround"
assert onnx_program.model_proto.functions[0].node[0].domain == "test.customop"
assert onnx_program.model_proto.functions[0].node[0].op_type == "CustomOpOne"
assert onnx_program.model_proto.functions[0].node[1].domain == "test.customop"
assert onnx_program.model_proto.functions[0].node[1].op_type == "CustomOpTwo"
This is how custom_addandround_model ONNX graph looks using Netron:
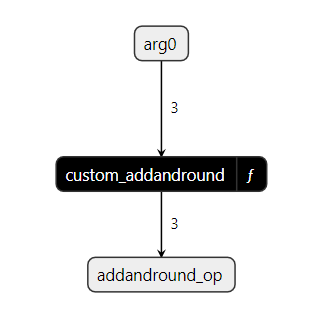
Inside the custom_addandround function, we can see the two custom operators we
used in the function (CustomOpOne, and CustomOpTwo), and they are from module
test.customop:
Custom Ops Registration in ONNX Runtime¶
To link your custom op library to ONNX Runtime, you need to compile your C++ code into a shared library and link it to ONNX Runtime. Follow the instructions below:
Implement your custom op in C++ by following ONNX Runtime instructions.
Download ONNX Runtime source distribution from ONNX Runtime releases.
Compile and link your custom op library to ONNX Runtime, for example:
$ gcc -shared -o libcustom_op_library.so custom_op_library.cc -L /path/to/downloaded/ort/lib/ -lonnxruntime -fPIC
Run the model with ONNX Runtime Python API and compare the results with PyTorch.
ort_session_options = onnxruntime.SessionOptions()
# NOTE: Link the custom op library to ONNX Runtime and replace the path
# with the path to your custom op library
ort_session_options.register_custom_ops_library(
"/path/to/libcustom_op_library.so"
)
ort_session = onnxruntime.InferenceSession(
"./custom_addandround_model.onnx", providers=['CPUExecutionProvider'], sess_options=ort_session_options)
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
onnx_input = onnx_program.adapt_torch_inputs_to_onnx(input_addandround_x)
onnxruntime_input = {k.name: to_numpy(v) for k, v in zip(ort_session.get_inputs(), onnx_input)}
onnxruntime_outputs = ort_session.run(None, onnxruntime_input)
torch_outputs = custom_addandround_model(input_addandround_x)
torch_outputs = onnx_program.adapt_torch_outputs_to_onnx(torch_outputs)
assert len(torch_outputs) == len(onnxruntime_outputs)
for torch_output, onnxruntime_output in zip(torch_outputs, onnxruntime_outputs):
torch.testing.assert_close(torch_output, torch.tensor(onnxruntime_output))
Conclusion¶
Congratulations! In this tutorial, we explored the ONNXRegistry API and
discovered how to create custom implementations for unsupported or existing ATen operators
using ONNX Script.
Finally, we leveraged ONNX Runtime to execute the model and compare the results with PyTorch,
providing us with a comprehensive understanding of handling unsupported
operators in the ONNX ecosystem.
Further reading¶
The list below refers to tutorials that ranges from basic examples to advanced scenarios, not necessarily in the order they are listed. Feel free to jump directly to specific topics of your interest or sit tight and have fun going through all of them to learn all there is about the ONNX exporter.
Total running time of the script: ( 0 minutes 0.000 seconds)
